
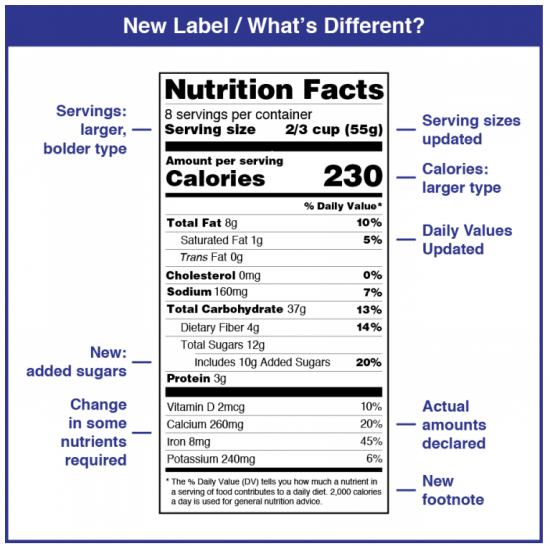
“Shouldn’t we, as a society, demand a nutrition label on our algorithms?” asked Dr. John Halamka.
Dr. Halamka, President of the Mayo Clinic Platform, was speaking at the HIMSS 2021 annual conference on the meeting’s digital channel. Artificial intelligence and health equity were two key themes discussed during #HIMSS21, and Dr. Halamka’s concerns echoed through the week-long event.
 To illustrate the need for a healthier approach to AI, he offered this scenario: “If I use a data set of one million Scandinavian Lutherans to create the most amazing EKG algorithm ever and then we decide to use it in Spain, is it going to work?”
To illustrate the need for a healthier approach to AI, he offered this scenario: “If I use a data set of one million Scandinavian Lutherans to create the most amazing EKG algorithm ever and then we decide to use it in Spain, is it going to work?”
His response to his own question: “This is our issue: the algorithms are only as good as the underlying training data. And yet, we don’t publish statistics with each algorithm describing how it was developed or it’s fit for purpose.”
What might such a description look like?
A nutrition label.
What’s underneath Dr. Halamka’s concerns?
Health care providers and payors are indeed adopting AI, with a sort of concerned embrace. “While other factors like lack of skilled data science professionals hold organizations back, the fact that 50 percent of time is spent on data preparation and deployment must be addressed before AI can be democratized and provide lasting value at scale in the health and life science industry,” IDC noted in a recent analysis on the so-called “data dilemma” and its impact on health care.
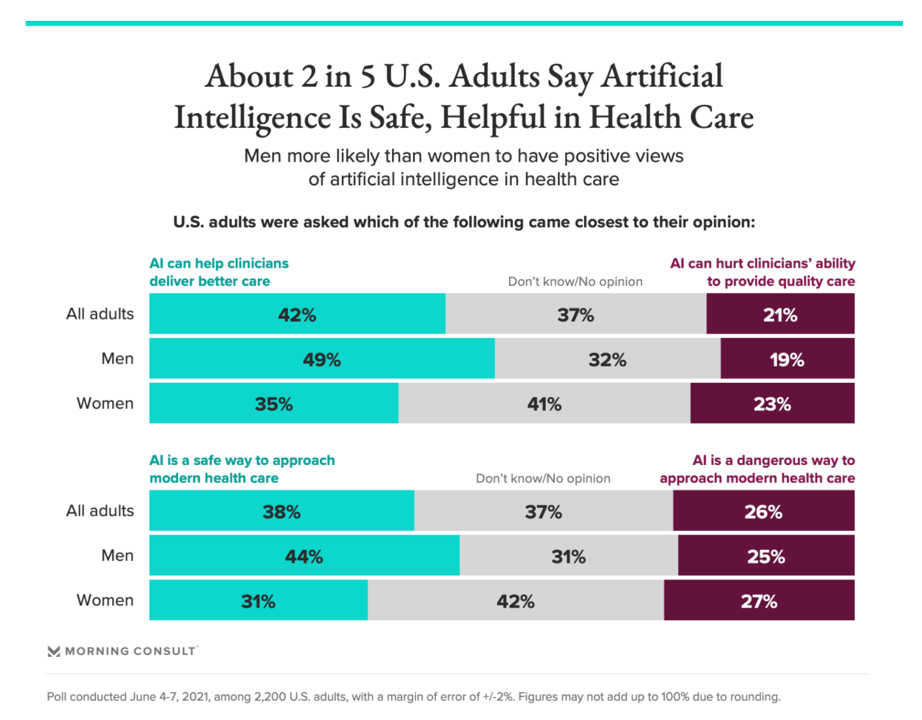 That’s the industry-health care enterprise point of view. From the health citizen’s point of view, a Morning Consult poll conducted in June 2021 found that while 2 in 5 US adult said AI is a safe way to approach modern health care. On the other hand, one-third of Americans didn’t have an opinion on the subject, and 26% of people saw AI as a “dangerous way to approach modern health care.”
That’s the industry-health care enterprise point of view. From the health citizen’s point of view, a Morning Consult poll conducted in June 2021 found that while 2 in 5 US adult said AI is a safe way to approach modern health care. On the other hand, one-third of Americans didn’t have an opinion on the subject, and 26% of people saw AI as a “dangerous way to approach modern health care.”
“Could advanced analytics automate racism in health care?” posed a July 2021 essay written by a team from Deloitte Consulting. While AI and machine learning have the potential to transform treatment decisions and identify rare diseases, they wrote, the technology could also exacerbate health inequities by “embedding the unconscious biases of human designers and developers,” they warned.
There are six ways bias can creep into health care algorithms, Deloitte itemized:
Technology design, as developers develop hypotheses to which their products are meant to respond. “Intentional designers should consider structural biases and adjust their problem statement and hypothesis accordingly,” Deloitte advises. A real-world example is pulse oximeters, which perform better on the skin of white people better than black people.
Data collection, ensuring that the information fed into the AI represent the population for which the solution is designed – per Dr. Halamka’s Scandinavia/Spain example.
Algorithm development, where developers should be attentive to transparency and “explainability.”
Implementation, with mechanisms for ongoing audits and evaluations of potential bias in the tools.
Usage, taking note of health care decisions made based on the algorithms to ensure inclusion as well as fair actions coming out of the recommendations.
Scaling and continuous feedback, continuing to adapt the models based on real-life experience that might have been overlooked in the original design.
![]() The Pew Trusts recently discussed prospects for the FDA to regulate AI in health care. The definition the Pew team set out was that AI “refers to the ability of a machine to perform a task that mimics human behavior, including problem-solving and learning.”
The Pew Trusts recently discussed prospects for the FDA to regulate AI in health care. The definition the Pew team set out was that AI “refers to the ability of a machine to perform a task that mimics human behavior, including problem-solving and learning.”
The Pew report also revealed concerns that could be addressed through regulation. One of the major worries is the risk that AI-enabled products could serve up potentially harmful or inaccurate treatment recommendations caused by bias in the information used to build or train the AI.
How could a nutrition label help to address this risk and bolster confidence in and competence from AI in health care?
What health IT can learn from the history of the nutrition label
Dr. Halamka described elements he would look to for populated the algorithmic nutrition label. In his description, the data descriptors could include race/ethnicity, gender, geography, income, among other elements. Ultimately, the label would display a statistical measure of how well the algorithm would work for a given patient population, he noted.
My colleague to whom I turn for data design and population health advice, Juhan Sonin, Founder of Goinvo Studios, provided this description when I asked him for his view on an AI nutrition label: in his words,
The underpants of the nutrition label
= knowing what’s in the model
= open models.
Open models allow us
to inspect for bias,
to inspect for accuracy,
to inspect for quality,
to inspect because it’s our damn health on the line.
The folks who imagined the original food nutrition label also believed our health was on the line.
In 1990, the Nutrition Labeling and Education Act was signed into law to help consumers make better choices and encourage food companies to produce healthier food, the International Food Information Center has documented in its history of the Nutrition Facts label. The NLEA required food manufacturers to develop a standardized Nutrition Facts label with information on serving size, calories, grams of fat, saturated fat, total carbohydrates, sugars, protein, and other ingredients “inside” the food package.
Even though the label appears to be a strict template, it was designed to be flexible to allow regulators to adapt to evolving nutrition knowledge based on a growing scientific evidence base.
That’s one remarkably useful metaphor for an algorithmic nutrition label.
Here’s another facet of this history that resonates with health data rights and equity. In the Progressive Era (from 1890 to 1920), regulation was focusing on preventing consumer fraud and in the case of food, preventing manufacturers from substituting sand for sugar, for example. “The idea was to protect the consumer from fraudulent and dangerous ingredients,” wrote Suzanne Junod, FDA historian (who, as an interesting aside, has written a fascinating essay on the history of regulation with a lens on the peanut butter and jelly sandwich).
Protecting consumers, in the case of algorithmic bias, has a two-fold objective: first, the clinical-medical goal of bolstering health outcomes and preventing adverse events or death; second, to bolster health equity and access to quality health care regardless of one’s race, ethnicity, gender, age, ZIP code, or other characteristic where bias can be introduced into an un-transparent black box.
 Building a nutrition label for health equity – learning from MITRE
Building a nutrition label for health equity – learning from MITRE
Questions about the ethics and governance of AI in health are being posed globally. The World Health Organization offered guidance earlier this year into the challenge, introducing its report with a perfect quote from Stephen Hawking: “Our future is a race between the growing power of technology and the wisdom with which we use it.”
WHO believes that while AI has enormous potential for strengthening health care delivery and benefit low- and middle-income countries (and health citizens, I would add), ethical considerations and human rights “must be placed at the centre of the design, development, and deployment of AI technologies for health,” WHO insists.
WHO’s key ethical principles for the use of AI for health echo those of The MITRE Corporation, which published a national strategy for digital health earlier this year. Among MITRE’s guiding principles for digital health are to empower individuals, act like every community and every person is important, collaborate and connect, and work toward improving health and well-being, among other objectives.
To realize these principles, MITRE offers up six goals which would be useful guideposts to adopt in developing a nutrition label that ensures equity and well-being in our health/care ecosystem:
- To ensure access, affordability, and utilization of universal broadband for everyone
- To enable a sustainable health workforce that is prepared to use new technologies to deliver person-centered, integrated quality care
- To design digital technologies that empower individuals to manage their health and well-being safely and securely
- To deploy data exchange architectures, application interfaces, and standards that put data, information, and education into the hands of those who need it, when they need it, reliable and securely
- To build a digital health ecosystem that delivers timely access to information to inform public health decision-making, and
- To implement integrated governance designed for the challenges of a digital health ecosystem.
Underpinning #6, with HIT nutrition on our minds, MITRE lists data protection, privacy, information security, patient rights, and transparency. Assuring these features will “cook up” health IT solutions for the benefit of health citizens and their health care providers.
Let me conclude our journey into the nutrition label for healthy algorithms returning to the wisdom of Juhan Sonin. His latest project, Own Your Health Data.Org, looks toward “a future we can trust,” which supports our personal health engagement and effective self-care.
As Juhan told me,
And when we own our health data,
… the kicker is…
You can own your algorithms and your health models.
You can then own your self-care.
We then come full-circle to meet up with the original intent of the Nutrition Facts label: to empower consumers (health citizens, all) for our nutrition and overall well-being.


 Thank you
Thank you  Jane joined host Dr. Geeta "Dr. G" Nayyar and colleagues to brainstorm the value of vaccines for public and individual health in this challenging environment for health literacy, health politics, and health citizen grievance.
Jane joined host Dr. Geeta "Dr. G" Nayyar and colleagues to brainstorm the value of vaccines for public and individual health in this challenging environment for health literacy, health politics, and health citizen grievance.